Limitations of Codebook Interpretability in Model-Based Reinforcement Learning
This paper by Kenneth Eaton, Jonathan Balloch, Julia Kim, and Mark Riedl discusses the constraints on the interpretability of codebooks within the framework of model-based reinforcement learning.

Academia Accelerated
17 views • Aug 18, 2024
About this video
The Interpretability of Codebooks in Model-Based Reinforcement Learning is Limited
Kenneth Eaton, Jonathan Balloch, Julia Kim, Mark Riedl
Original Paper: https://arxiv.org/abs/2407.19532
InteOriginal paper: https://arxiv.org/abs/2407.19532
Title: The Interpretability of Codebooks in Model-Based Reinforcement Learning is Limited
Authors: Kenneth Eaton, Jonathan Balloch, Julia Kim, Mark Riedl
Abstract:
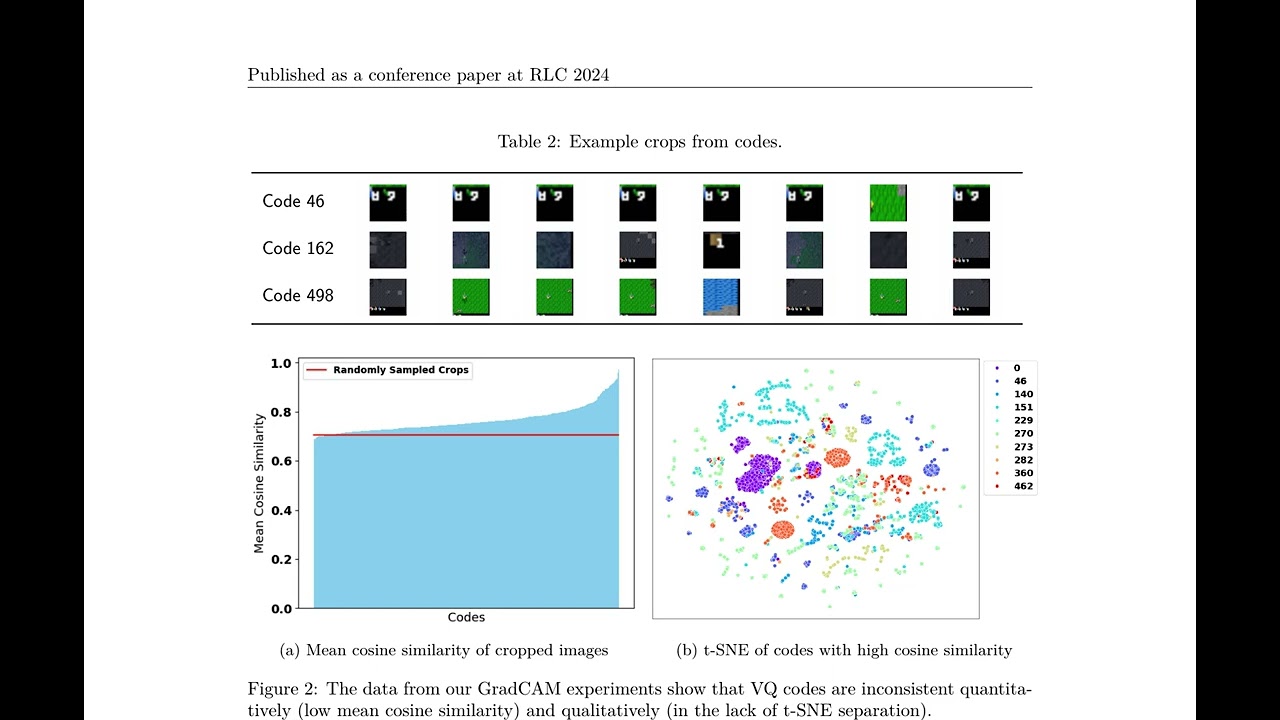
Interpretability of deep reinforcement learning systems could assist operators with understanding how they interact with their environment. Vector quantization methods -- also called codebook methods -- discretize a neural network's latent space that is often suggested to yield emergent interpretability. We investigate whether vector quantization in fact provides interpretability in model-based reinforcement learning. Our experiments, conducted in the reinforcement learning environment Crafter, show that the codes of vector quantization models are inconsistent, have no guarantee of uniqueness, and have a limited impact on concept disentanglement, all of which are necessary traits for interpretability. We share insights on why vector quantization may be fundamentally insufficient for model interpretability.
interact with their environment. Vector quantization methods -- also called codebook methods -- discretize a neural network's latent space that is often suggested to yield emergent interpretability. We investigate whether vector quantization in fact provides interpretability in model-based reinforcement learning. Our experiments, conducted in the reinforcement learning environment Crafter, show that the codes of vector quantization models are inconsistent, have no guarantee of uniqueness, and have a limited impact on concept disentanglement, all of which are necessary traits for interpretability. We share insights on why vector quantization may be fundamentally insufficient for model interpretability.
Kenneth Eaton, Jonathan Balloch, Julia Kim, Mark Riedl
Original Paper: https://arxiv.org/abs/2407.19532
InteOriginal paper: https://arxiv.org/abs/2407.19532
Title: The Interpretability of Codebooks in Model-Based Reinforcement Learning is Limited
Authors: Kenneth Eaton, Jonathan Balloch, Julia Kim, Mark Riedl
Abstract:
Interpretability of deep reinforcement learning systems could assist operators with understanding how they interact with their environment. Vector quantization methods -- also called codebook methods -- discretize a neural network's latent space that is often suggested to yield emergent interpretability. We investigate whether vector quantization in fact provides interpretability in model-based reinforcement learning. Our experiments, conducted in the reinforcement learning environment Crafter, show that the codes of vector quantization models are inconsistent, have no guarantee of uniqueness, and have a limited impact on concept disentanglement, all of which are necessary traits for interpretability. We share insights on why vector quantization may be fundamentally insufficient for model interpretability.
interact with their environment. Vector quantization methods -- also called codebook methods -- discretize a neural network's latent space that is often suggested to yield emergent interpretability. We investigate whether vector quantization in fact provides interpretability in model-based reinforcement learning. Our experiments, conducted in the reinforcement learning environment Crafter, show that the codes of vector quantization models are inconsistent, have no guarantee of uniqueness, and have a limited impact on concept disentanglement, all of which are necessary traits for interpretability. We share insights on why vector quantization may be fundamentally insufficient for model interpretability.
Video Information
Views
17
Duration
12:08
Published
Aug 18, 2024
Related Trending Topics
LIVE TRENDSRelated trending topics. Click any trend to explore more videos.
No specific trending topics match this video yet.
Explore All Trends