Are Generator-Coroutines the Future of Python? Insights from PyData London 2024 ⚡
Discover whether generator-coroutines are the ultimate solution for asynchronous programming in Python. Join James Powell at PyData London 2024 to explore their potential and limitations.
PyData
5.8K views • Jun 21, 2024
About this video
www.pydata.org
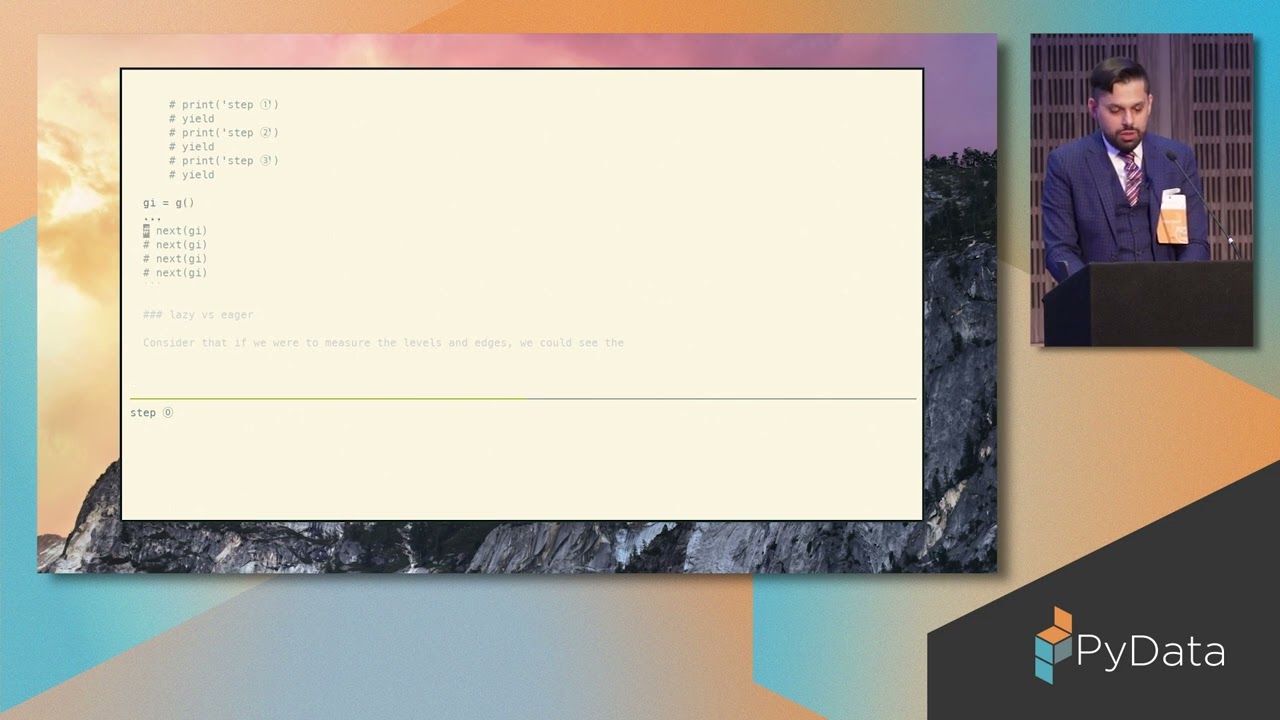
As we all know (or, at least, as I've been trying to tell everyone,) generators in Python are an extremely powerful API design technique. A generator represents the linear decomposition of a single computation into multiple parts, and such decomposition proves very useful in practice. For example, we can model an infinite computation and only execute the portions we desire. Very similarly, we can simplify APIs that specify when a computation terminates, by modeling these computations as infinite sequences of steps, and allowing the end-user to directly control which steps are peformed. We can even interleave the parts of multiple, distinct computations (though in Python ≥3.6, this is better done with the custom async and await syntax and associated protocols.)
A generator-coroutine offers us an alternative formulation for a state machine, but one which represents state and transitions implicitly in the form of (linearised) source text—in order words, a state machine that we can read and understand like any other regular code (and where we have arbitrary control over data-flow.)
But, in practice, the principles which support the use of generators (e.g., as iteration helpers,) often contrast with the code we get when we model with generator-coroutines, and a number of practical issues arise. While these issues may be surmountable (with enough effort and enough contortion,) the question remains: are generator-coroutines really the answer?
PyData is an educational program of NumFOCUS, a 501(c)3 non-profit organization in the United States. PyData provides a forum for the international community of users and developers of data analysis tools to share ideas and learn from each other. The global PyData network promotes discussion of best practices, new approaches, and emerging technologies for data management, processing, analytics, and visualization. PyData communities approach data science using many languages, including (but not limited to) Python, Julia, and R.
PyData conferences aim to be accessible and community-driven, with novice to advanced level presentations. PyData tutorials and talks bring attendees the latest project features along with cutting-edge use cases.
00:00 Welcome!
00:10 Help us add time stamps or captions to this video! See the description for details.
Want to help add timestamps to our YouTube videos to help with discoverability? Find out more here: https://github.com/numfocus/YouTubeVideoTimestamps
As we all know (or, at least, as I've been trying to tell everyone,) generators in Python are an extremely powerful API design technique. A generator represents the linear decomposition of a single computation into multiple parts, and such decomposition proves very useful in practice. For example, we can model an infinite computation and only execute the portions we desire. Very similarly, we can simplify APIs that specify when a computation terminates, by modeling these computations as infinite sequences of steps, and allowing the end-user to directly control which steps are peformed. We can even interleave the parts of multiple, distinct computations (though in Python ≥3.6, this is better done with the custom async and await syntax and associated protocols.)
A generator-coroutine offers us an alternative formulation for a state machine, but one which represents state and transitions implicitly in the form of (linearised) source text—in order words, a state machine that we can read and understand like any other regular code (and where we have arbitrary control over data-flow.)
But, in practice, the principles which support the use of generators (e.g., as iteration helpers,) often contrast with the code we get when we model with generator-coroutines, and a number of practical issues arise. While these issues may be surmountable (with enough effort and enough contortion,) the question remains: are generator-coroutines really the answer?
PyData is an educational program of NumFOCUS, a 501(c)3 non-profit organization in the United States. PyData provides a forum for the international community of users and developers of data analysis tools to share ideas and learn from each other. The global PyData network promotes discussion of best practices, new approaches, and emerging technologies for data management, processing, analytics, and visualization. PyData communities approach data science using many languages, including (but not limited to) Python, Julia, and R.
PyData conferences aim to be accessible and community-driven, with novice to advanced level presentations. PyData tutorials and talks bring attendees the latest project features along with cutting-edge use cases.
00:00 Welcome!
00:10 Help us add time stamps or captions to this video! See the description for details.
Want to help add timestamps to our YouTube videos to help with discoverability? Find out more here: https://github.com/numfocus/YouTubeVideoTimestamps
Tags and Topics
Browse our collection to discover more content in these categories.
Video Information
Views
5.8K
Likes
97
Duration
42:04
Published
Jun 21, 2024
User Reviews
4.6
(1) Related Trending Topics
LIVE TRENDSRelated trending topics. Click any trend to explore more videos.
No specific trending topics match this video yet.
Explore All Trends