Hadoop Installation Series: How to Start Hadoop and Its Components 🚀
Learn step-by-step how to start Hadoop and its essential components using start-dfs.sh, including NameNode and DataNode setup for a smooth Hadoop environment.
Saqib24x7
44 views • Jun 18, 2014
About this video
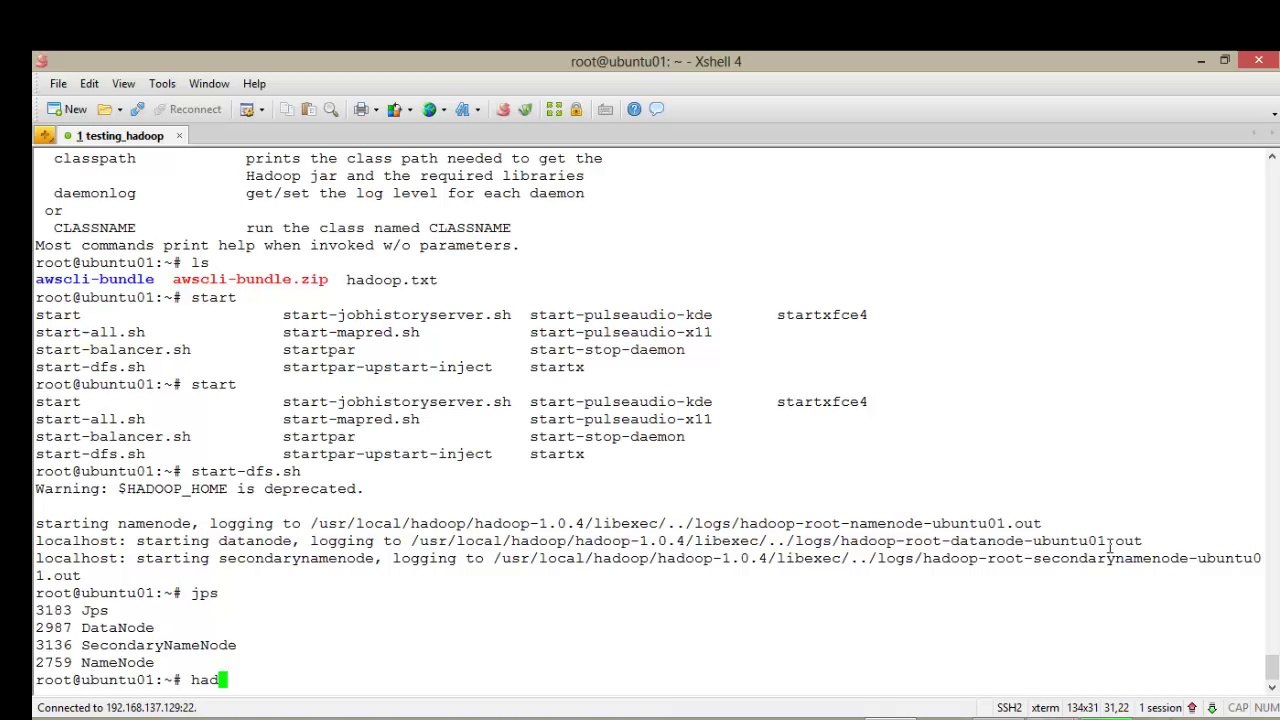
The start-dfs.sh command, as the name suggests, starts the components necessary for <br />HDFS. This is the NameNode to manage the filesystem and a single DataNode to hold data. <br /> <br />The SecondaryNameNode is an availability aid that we'll discuss in a later chapter. <br /> <br />After starting these components, we use the JDK's jps utility to see which Java processes are <br />running, and, as the output looks good, we then use Hadoop's dfs utility to list the root of <br />the HDFS filesystem. <br /> <br />After this, we use start-mapred.sh to start the MapReduce components—this time the <br />JobTracker and a single TaskTracker—and then use jps again to verify the result. <br /> <br />There is also a combined start-all.sh file that we'll use at a later stage, but in the early <br />days it's useful to do a two-stage start up to more easily verify the cluster configuration.
Video Information
Views
44
Duration
1:19
Published
Jun 18, 2014
Related Trending Topics
LIVE TRENDSRelated trending topics. Click any trend to explore more videos.