Tokenization & Embeddings in Transformers 🧠
Learn how tokenization and embeddings prepare data for self-attention in transformer models, starting with simple sentences like 'the quick brown fox.'

Stephen Blum
2.0K views • Jul 25, 2024
About this video
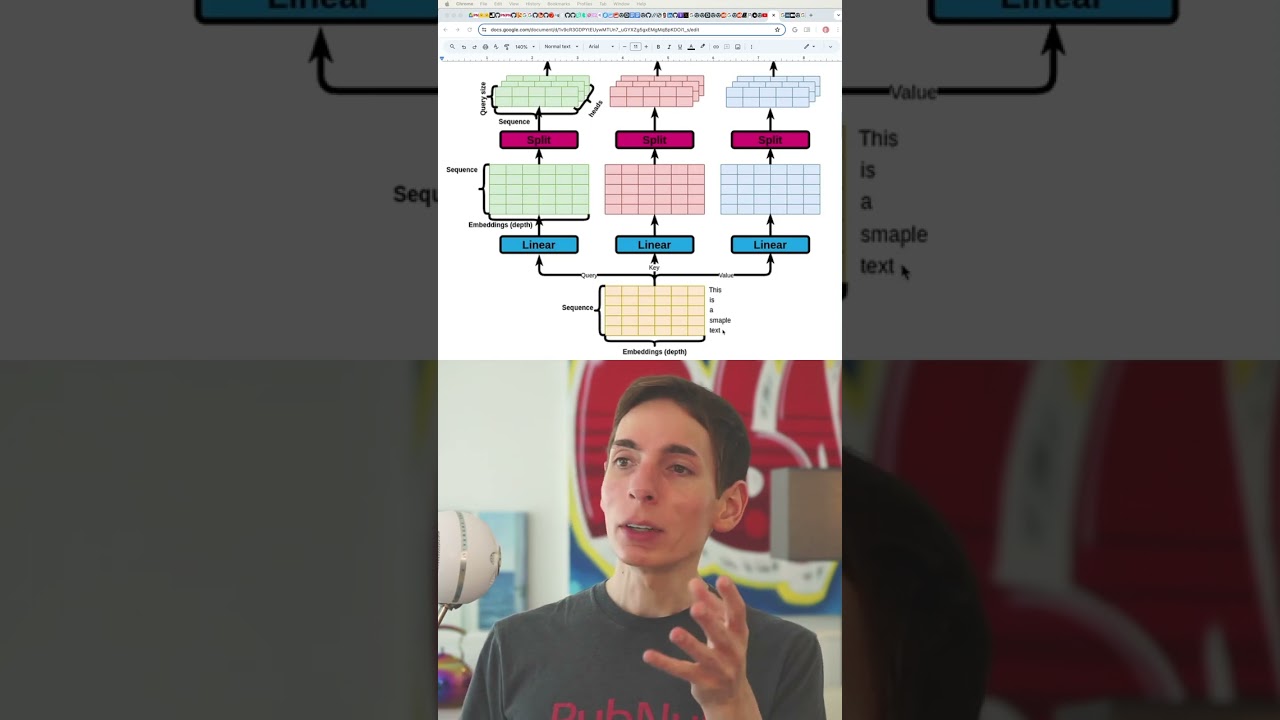
Before self-attention in the transformer model, there's a phase called data preparation. Let's say we have a simple sentence like "the quick brown fox." Each word is a token. First, we tokenize the sentence, splitting it into individual words.
Each token is then converted into an ID using a model like word2vec. For example, "the" might be ID 200. This ID is then used in a word embedding model that shows the relationships between words.
The word embedding turns each token into an array, possibly 512 floating-point numbers, describing its attributes. These arrays are then copied as the query, key, and value for the self-attention mechanism.
Each token is then converted into an ID using a model like word2vec. For example, "the" might be ID 200. This ID is then used in a word embedding model that shows the relationships between words.
The word embedding turns each token into an array, possibly 512 floating-point numbers, describing its attributes. These arrays are then copied as the query, key, and value for the self-attention mechanism.
Tags and Topics
Browse our collection to discover more content in these categories.
Video Information
Views
2.0K
Likes
47
Duration
1:00
Published
Jul 25, 2024
User Reviews
4.5
(1) Related Trending Topics
LIVE TRENDSRelated trending topics. Click any trend to explore more videos.
No specific trending topics match this video yet.
Explore All Trends