THInImg: Innovative Cross-Modal Steganography for Realistic Talking Head Images 🎥
Discover how THInImg leverages cross-modal steganography to seamlessly embed secret signals into images of talking heads, enhancing privacy and security in visual communications.

ComputerVisionFoundation Videos
16 views • Jan 30, 2024
About this video
Authors: Lin Zhao; Hongxuan Li; Xuefei Ning; Xinru Jiang
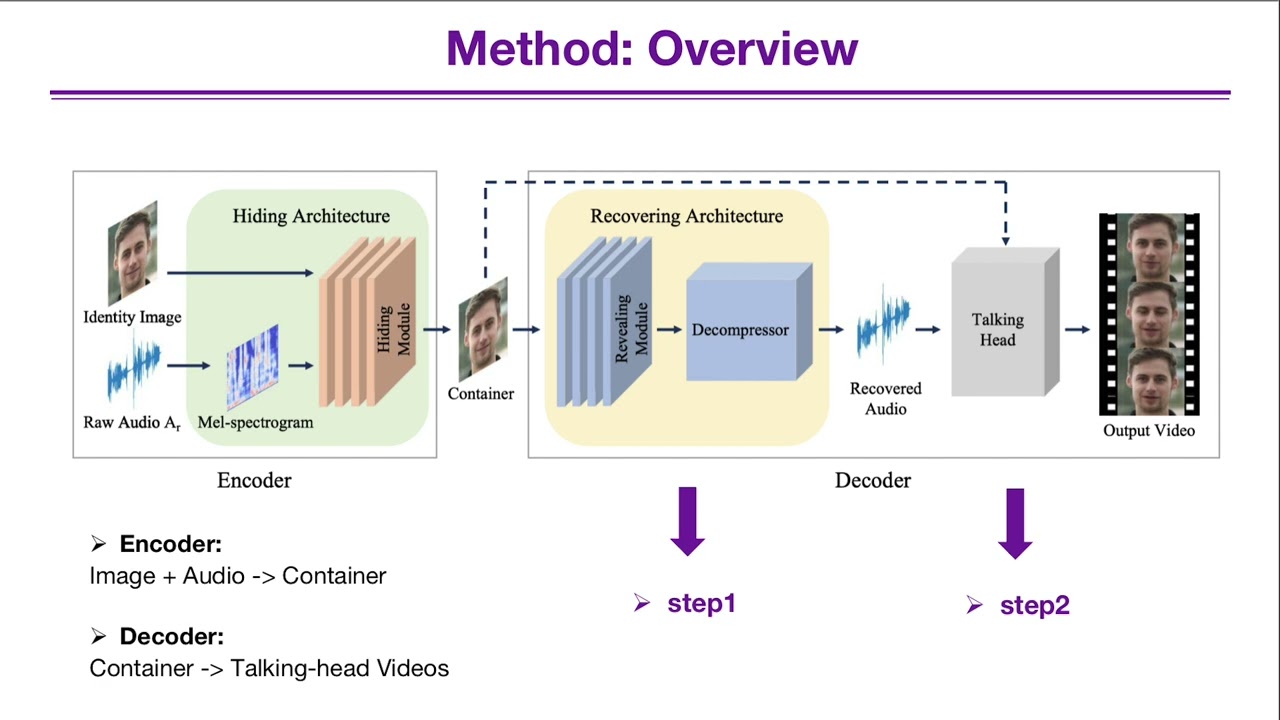
Description: Cross-modal Steganography is the practice of concealing secret signals in publicly available cover signals (distinct from the modality of the secret signals) unobtrusively. While previous approaches primarily concentrated on concealing a relatively small amount of information, we propose THInImg, which manages to hide lengthy audio data (and subsequently decode talking head video) inside an identity image by leveraging the properties of human face, which can be effectively utilized for covert communication, transmission and copyright protection. THInImg consists of two parts: the encoder and decoder. Inside the encoder-decoder pipeline, we introduce a novel architecture that substantially increase the capacity of hiding audio in images. Moreover, our framework can be extended to iteratively hide multiple audio clips into an identity image, offering multiple levels of control over permissions. We conduct extensive experiments to prove the effectiveness of our method, demonstrating that THInImg can present up to 80 seconds of high quality talking-head video (including audio) in an identity image with 160×160 resolution.
Description: Cross-modal Steganography is the practice of concealing secret signals in publicly available cover signals (distinct from the modality of the secret signals) unobtrusively. While previous approaches primarily concentrated on concealing a relatively small amount of information, we propose THInImg, which manages to hide lengthy audio data (and subsequently decode talking head video) inside an identity image by leveraging the properties of human face, which can be effectively utilized for covert communication, transmission and copyright protection. THInImg consists of two parts: the encoder and decoder. Inside the encoder-decoder pipeline, we introduce a novel architecture that substantially increase the capacity of hiding audio in images. Moreover, our framework can be extended to iteratively hide multiple audio clips into an identity image, offering multiple levels of control over permissions. We conduct extensive experiments to prove the effectiveness of our method, demonstrating that THInImg can present up to 80 seconds of high quality talking-head video (including audio) in an identity image with 160×160 resolution.
Video Information
Views
16
Duration
6:45
Published
Jan 30, 2024
Related Trending Topics
LIVE TRENDSRelated trending topics. Click any trend to explore more videos.