Scikit-learn Preprocessing Techniques for ML ⚡
Learn key preprocessing methods like StandardScaler in scikit-learn to improve your machine learning models' performance.

CodeVisium
1.4K views • Sep 29, 2025
About this video
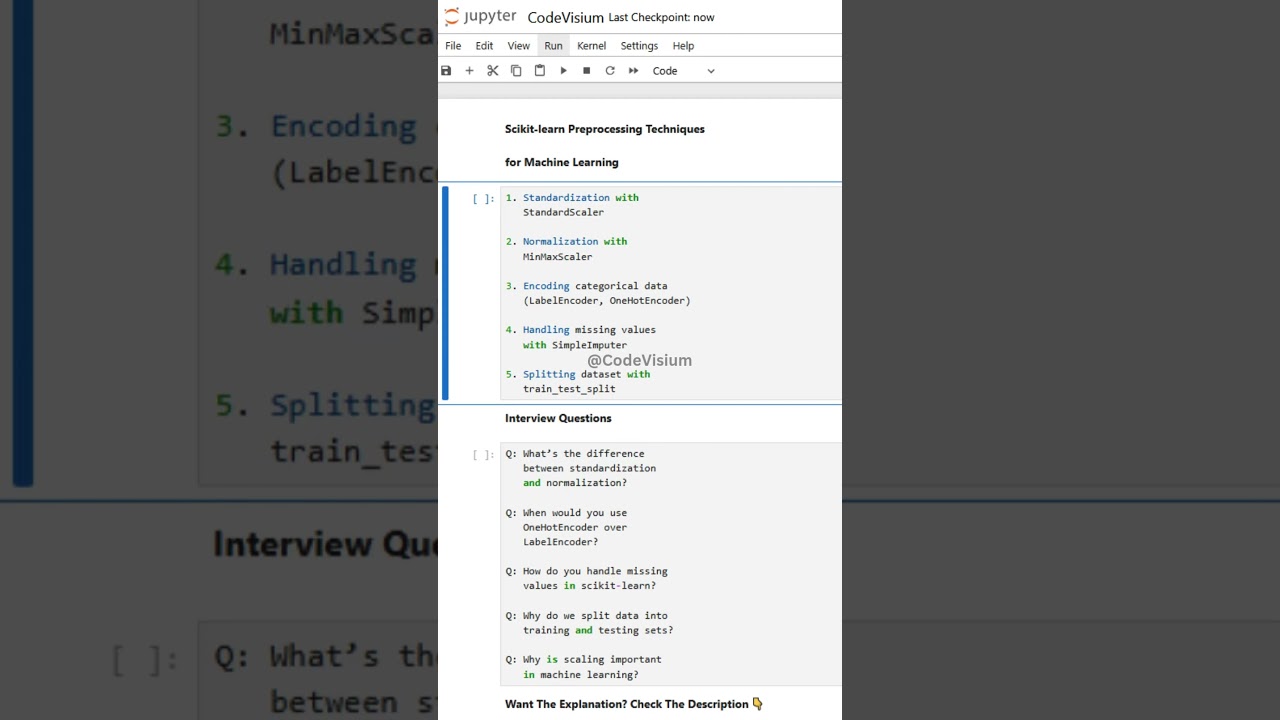
1. Standardization with StandardScaler
Standardization transforms data so that it has mean = 0 and standard deviation = 1, which helps many ML algorithms converge faster.
# Long form
from sklearn.preprocessing import StandardScaler
import numpy as np
data = np.array([[1,2],[3,4],[5,6]])
scaler = StandardScaler()
scaled = scaler.fit_transform(data)
# One-liner
scaled = __import__('sklearn.preprocessing').StandardScaler().fit_transform([[1,2],[3,4],[5,6]])
This ensures features are on the same scale, improving model performance.
2. Normalization with MinMaxScaler
Normalization scales features to a specific range (usually [0,1]), often required for neural networks.
# Long form
from sklearn.preprocessing import MinMaxScaler
data = [[1,2],[3,4],[5,6]]
scaler = MinMaxScaler()
normalized = scaler.fit_transform(data)
# One-liner
normalized = __import__('sklearn.preprocessing').MinMaxScaler().fit_transform([[1,2],[3,4],[5,6]])
It ensures all features contribute equally to model training.
3. Encoding categorical data
Machine learning models can’t handle strings, so categorical values must be encoded.
# Long form
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
import numpy as np
labels = ['cat','dog','cat','bird']
label_enc = LabelEncoder().fit_transform(labels)
onehot_enc = OneHotEncoder(sparse=False).fit_transform(np.array(labels).reshape(-1,1))
# One-liner
le,oh = __import__('sklearn.preprocessing').LabelEncoder().fit_transform(['cat','dog','cat','bird']), __import__('sklearn.preprocessing').OneHotEncoder(sparse=False).fit_transform(np.array(['cat','dog','cat','bird']).reshape(-1,1))
Label encoding converts categories into numbers, while one-hot encoding creates binary vectors.
4. Handling missing values with SimpleImputer
Missing data is common in real-world datasets, and imputers can replace them with mean, median, or a constant.
# Long form
from sklearn.impute import SimpleImputer
import numpy as np
data = [[1,2],[np.nan,3],[7,6]]
imputer = SimpleImputer(strategy='mean')
imputed = imputer.fit_transform(data)
# One-liner
imputed = __import__('sklearn.impute').SimpleImputer(strategy='mean').fit_transform([[1,2],[None,3],[7,6]])
This prevents models from failing due to NaN values.
5. Splitting dataset with train_test_split
Splitting datasets into training and testing sets ensures unbiased evaluation of models.
# Long form
from sklearn.model_selection import train_test_split
X = [[1],[2],[3],[4],[5]]
y = [0,0,1,1,1]
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.2,random_state=42)
# One-liner
X_train,X_test,y_train,y_test = __import__('sklearn.model_selection').train_test_split([[1],[2],[3],[4],[5]],[0,0,1,1,1],test_size=0.2,random_state=42)
This is crucial for avoiding overfitting and ensuring reliable performance metrics.
5 Interview Questions (with Answers):
Q: What’s the difference between standardization and normalization?
A: Standardization → mean=0, std=1. Normalization → rescaling features to a fixed range (e.g., [0,1]).
Q: When would you use OneHotEncoder over LabelEncoder?
A: Use OneHotEncoder when categories don’t have an inherent order (e.g., colors), LabelEncoder when order matters.
Q: How do you handle missing values in scikit-learn?
A: Using SimpleImputer with strategies like mean, median, or most frequent.
Q: Why do we split data into training and testing sets?
A: To evaluate model performance on unseen data and prevent overfitting.
Q: Why is scaling important in machine learning?
A: Many algorithms (e.g., KNN, SVM, Gradient Descent) are sensitive to feature scales, so scaling ensures fair contribution.
#scikitlearn #Python #MachineLearning #DataScience #MLTips #CodingTips #InterviewPrep
Standardization transforms data so that it has mean = 0 and standard deviation = 1, which helps many ML algorithms converge faster.
# Long form
from sklearn.preprocessing import StandardScaler
import numpy as np
data = np.array([[1,2],[3,4],[5,6]])
scaler = StandardScaler()
scaled = scaler.fit_transform(data)
# One-liner
scaled = __import__('sklearn.preprocessing').StandardScaler().fit_transform([[1,2],[3,4],[5,6]])
This ensures features are on the same scale, improving model performance.
2. Normalization with MinMaxScaler
Normalization scales features to a specific range (usually [0,1]), often required for neural networks.
# Long form
from sklearn.preprocessing import MinMaxScaler
data = [[1,2],[3,4],[5,6]]
scaler = MinMaxScaler()
normalized = scaler.fit_transform(data)
# One-liner
normalized = __import__('sklearn.preprocessing').MinMaxScaler().fit_transform([[1,2],[3,4],[5,6]])
It ensures all features contribute equally to model training.
3. Encoding categorical data
Machine learning models can’t handle strings, so categorical values must be encoded.
# Long form
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
import numpy as np
labels = ['cat','dog','cat','bird']
label_enc = LabelEncoder().fit_transform(labels)
onehot_enc = OneHotEncoder(sparse=False).fit_transform(np.array(labels).reshape(-1,1))
# One-liner
le,oh = __import__('sklearn.preprocessing').LabelEncoder().fit_transform(['cat','dog','cat','bird']), __import__('sklearn.preprocessing').OneHotEncoder(sparse=False).fit_transform(np.array(['cat','dog','cat','bird']).reshape(-1,1))
Label encoding converts categories into numbers, while one-hot encoding creates binary vectors.
4. Handling missing values with SimpleImputer
Missing data is common in real-world datasets, and imputers can replace them with mean, median, or a constant.
# Long form
from sklearn.impute import SimpleImputer
import numpy as np
data = [[1,2],[np.nan,3],[7,6]]
imputer = SimpleImputer(strategy='mean')
imputed = imputer.fit_transform(data)
# One-liner
imputed = __import__('sklearn.impute').SimpleImputer(strategy='mean').fit_transform([[1,2],[None,3],[7,6]])
This prevents models from failing due to NaN values.
5. Splitting dataset with train_test_split
Splitting datasets into training and testing sets ensures unbiased evaluation of models.
# Long form
from sklearn.model_selection import train_test_split
X = [[1],[2],[3],[4],[5]]
y = [0,0,1,1,1]
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.2,random_state=42)
# One-liner
X_train,X_test,y_train,y_test = __import__('sklearn.model_selection').train_test_split([[1],[2],[3],[4],[5]],[0,0,1,1,1],test_size=0.2,random_state=42)
This is crucial for avoiding overfitting and ensuring reliable performance metrics.
5 Interview Questions (with Answers):
Q: What’s the difference between standardization and normalization?
A: Standardization → mean=0, std=1. Normalization → rescaling features to a fixed range (e.g., [0,1]).
Q: When would you use OneHotEncoder over LabelEncoder?
A: Use OneHotEncoder when categories don’t have an inherent order (e.g., colors), LabelEncoder when order matters.
Q: How do you handle missing values in scikit-learn?
A: Using SimpleImputer with strategies like mean, median, or most frequent.
Q: Why do we split data into training and testing sets?
A: To evaluate model performance on unseen data and prevent overfitting.
Q: Why is scaling important in machine learning?
A: Many algorithms (e.g., KNN, SVM, Gradient Descent) are sensitive to feature scales, so scaling ensures fair contribution.
#scikitlearn #Python #MachineLearning #DataScience #MLTips #CodingTips #InterviewPrep
Tags and Topics
Browse our collection to discover more content in these categories.
Video Information
Views
1.4K
Likes
20
Duration
0:10
Published
Sep 29, 2025
User Reviews
4.4
(1) Related Trending Topics
LIVE TRENDSRelated trending topics. Click any trend to explore more videos.
No specific trending topics match this video yet.
Explore All Trends