NLTK Python Tutorial for Beginners 📚
Learn how to use NLTK, a powerful Python library, for processing human language data. Download the code from codegive.com.

CodeGen
2 views • Jan 31, 2024
About this video
Download this code from https://codegive.com
Natural Language Toolkit (NLTK) is a powerful library for working with human language data in Python. It provides easy-to-use interfaces to over 50 corpora and lexical resources, such as WordNet. NLTK also includes text processing libraries for classification, tokenization, stemming, tagging, parsing, and more. In this tutorial, we will cover some fundamental concepts and functionalities of NLTK with code examples.
First, you need to install NLTK. Open your terminal or command prompt and run:
Once NLTK is installed, you need to download additional resources like corpora and models. Open a Python shell or script and run the following commands:
Now, you are ready to explore NLTK's capabilities.
Tokenization is the process of breaking down a text into words or sentences. NLTK provides a word_tokenize function for word tokenization and a sent_tokenize function for sentence tokenization.
Part-of-speech tagging involves labeling each word in a sentence with its part of speech, such as noun, verb, adjective, etc.
NER involves identifying entities such as names, locations, and organizations in text.
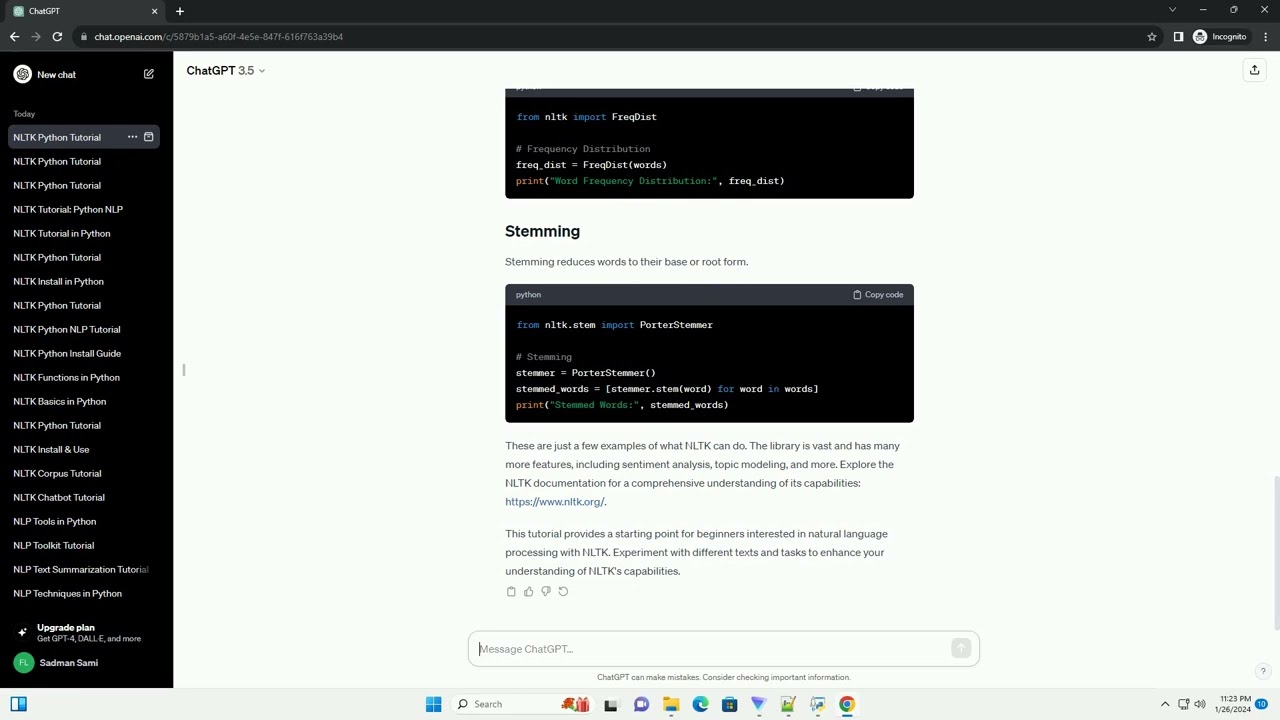
NLTK provides a convenient way to analyze the frequency distribution of words in a text.
Stemming reduces words to their base or root form.
These are just a few examples of what NLTK can do. The library is vast and has many more features, including sentiment analysis, topic modeling, and more. Explore the NLTK documentation for a comprehensive understanding of its capabilities: https://www.nltk.org/.
This tutorial provides a starting point for beginners interested in natural language processing with NLTK. Experiment with different texts and tasks to enhance your understanding of NLTK's capabilities.
ChatGPT
Natural Language Toolkit (NLTK) is a powerful library for working with human language data in Python. It provides easy-to-use interfaces to over 50 corpora and lexical resources, such as WordNet. NLTK also includes text processing libraries for classification, tokenization, stemming, tagging, parsing, and more. In this tutorial, we will cover some fundamental concepts and functionalities of NLTK with code examples.
First, you need to install NLTK. Open your terminal or command prompt and run:
Once NLTK is installed, you need to download additional resources like corpora and models. Open a Python shell or script and run the following commands:
Now, you are ready to explore NLTK's capabilities.
Tokenization is the process of breaking down a text into words or sentences. NLTK provides a word_tokenize function for word tokenization and a sent_tokenize function for sentence tokenization.
Part-of-speech tagging involves labeling each word in a sentence with its part of speech, such as noun, verb, adjective, etc.
NER involves identifying entities such as names, locations, and organizations in text.
NLTK provides a convenient way to analyze the frequency distribution of words in a text.
Stemming reduces words to their base or root form.
These are just a few examples of what NLTK can do. The library is vast and has many more features, including sentiment analysis, topic modeling, and more. Explore the NLTK documentation for a comprehensive understanding of its capabilities: https://www.nltk.org/.
This tutorial provides a starting point for beginners interested in natural language processing with NLTK. Experiment with different texts and tasks to enhance your understanding of NLTK's capabilities.
ChatGPT
Tags and Topics
Browse our collection to discover more content in these categories.
Video Information
Views
2
Duration
3:28
Published
Jan 31, 2024
Related Trending Topics
LIVE TRENDSRelated trending topics. Click any trend to explore more videos.
No specific trending topics match this video yet.
Explore All Trends