Top Python Interview Questions for Data Analysts & Scientists 🚀
Explore 5 advanced Python interview questions with detailed answers for data analysts and scientists. Prepare effectively! #Python #DataScience

CodeVisium
129 views • Mar 30, 2025
About this video
Here are 5 advanced Python interview questions tailored for data analysts and data scientists, with detailed answers:
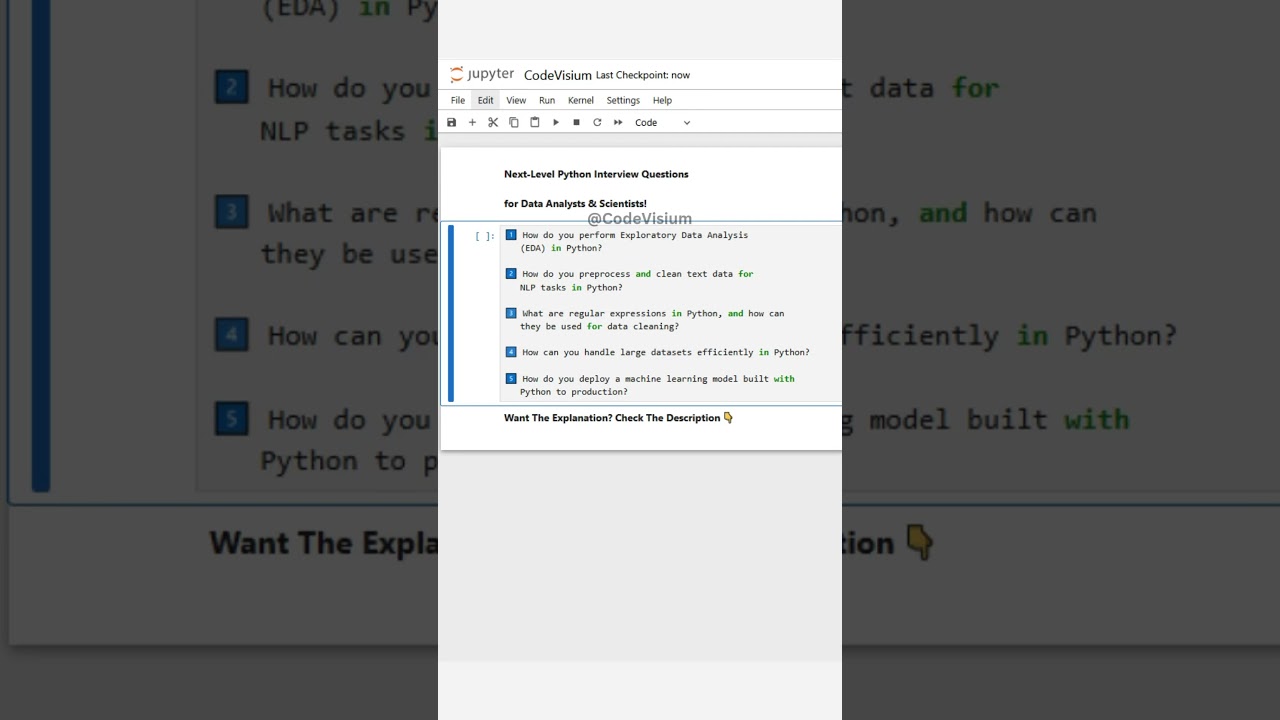
1️⃣ How do you perform Exploratory Data Analysis (EDA) in Python?
EDA involves summarizing the main characteristics of a dataset using statistical graphics and visualization tools.
Tools include pandas, Matplotlib, Seaborn, and automated reports like pandas-profiling.
Example:
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
df = pd.read_csv("data.csv")
print(df.describe())
sns.pairplot(df)
plt.show()
2️⃣ How do you preprocess and clean text data for NLP tasks in Python?
Text preprocessing includes lowercasing, removing punctuation, stopwords, tokenization, and stemming/lemmatization.
Libraries like NLTK and spaCy are commonly used.
Example:
import nltk
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
nltk.download('punkt')
nltk.download('stopwords')
text = "Python is great for data science!"
tokens = word_tokenize(text.lower())
tokens = [word for word in tokens if word.isalpha()]
tokens = [word for word in tokens if word not in stopwords.words('english')]
print(tokens) # Output: ['python', 'great', 'data', 'science']
3️⃣ What are regular expressions in Python, and how can they be used for data cleaning?
Regular expressions (regex) allow pattern matching and extraction in text.
They’re used to clean, validate, and extract information from messy data.
Example:
import re
text = "User: john_doe123, Email: john.doe@example.com"
email_pattern = r'[\w\.-]+@[\w\.-]+'
emails = re.findall(email_pattern, text)
print(emails) # Output: ['john.doe@example.com']
4️⃣ How can you handle large datasets efficiently in Python?
For big data, libraries like Dask and PySpark enable parallel computing and out-of-core processing.
Dask mimics the pandas API but works with data in chunks.
Example using Dask:
import dask.dataframe as dd
df = dd.read_csv("large_dataset.csv")
df_summary = df.describe().compute()
print(df_summary)
5️⃣ How do you deploy a machine learning model built with Python to production?
Deployment can be achieved using Flask or FastAPI to create REST APIs.
Tools like Docker help containerize the model, while cloud services (AWS, GCP) facilitate scaling.
Example with Flask:
from flask import Flask, request, jsonify
import pickle
app = Flask(__name__)
model = pickle.load(open("model.pkl", "rb"))
@app.route('/predict', methods=['POST'])
def predict():
data = request.get_json(force=True)
prediction = model.predict([data["features"]])
return jsonify(prediction.tolist())
if __name__ == '__main__':
app.run(debug=True)
💡 Follow for more Python interview tips and data science insights! 🚀
#Python #DataScience #DataAnalysis #NLP #BigData #MachineLearning #InterviewQuestions
1️⃣ How do you perform Exploratory Data Analysis (EDA) in Python?
EDA involves summarizing the main characteristics of a dataset using statistical graphics and visualization tools.
Tools include pandas, Matplotlib, Seaborn, and automated reports like pandas-profiling.
Example:
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
df = pd.read_csv("data.csv")
print(df.describe())
sns.pairplot(df)
plt.show()
2️⃣ How do you preprocess and clean text data for NLP tasks in Python?
Text preprocessing includes lowercasing, removing punctuation, stopwords, tokenization, and stemming/lemmatization.
Libraries like NLTK and spaCy are commonly used.
Example:
import nltk
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
nltk.download('punkt')
nltk.download('stopwords')
text = "Python is great for data science!"
tokens = word_tokenize(text.lower())
tokens = [word for word in tokens if word.isalpha()]
tokens = [word for word in tokens if word not in stopwords.words('english')]
print(tokens) # Output: ['python', 'great', 'data', 'science']
3️⃣ What are regular expressions in Python, and how can they be used for data cleaning?
Regular expressions (regex) allow pattern matching and extraction in text.
They’re used to clean, validate, and extract information from messy data.
Example:
import re
text = "User: john_doe123, Email: john.doe@example.com"
email_pattern = r'[\w\.-]+@[\w\.-]+'
emails = re.findall(email_pattern, text)
print(emails) # Output: ['john.doe@example.com']
4️⃣ How can you handle large datasets efficiently in Python?
For big data, libraries like Dask and PySpark enable parallel computing and out-of-core processing.
Dask mimics the pandas API but works with data in chunks.
Example using Dask:
import dask.dataframe as dd
df = dd.read_csv("large_dataset.csv")
df_summary = df.describe().compute()
print(df_summary)
5️⃣ How do you deploy a machine learning model built with Python to production?
Deployment can be achieved using Flask or FastAPI to create REST APIs.
Tools like Docker help containerize the model, while cloud services (AWS, GCP) facilitate scaling.
Example with Flask:
from flask import Flask, request, jsonify
import pickle
app = Flask(__name__)
model = pickle.load(open("model.pkl", "rb"))
@app.route('/predict', methods=['POST'])
def predict():
data = request.get_json(force=True)
prediction = model.predict([data["features"]])
return jsonify(prediction.tolist())
if __name__ == '__main__':
app.run(debug=True)
💡 Follow for more Python interview tips and data science insights! 🚀
#Python #DataScience #DataAnalysis #NLP #BigData #MachineLearning #InterviewQuestions
Tags and Topics
Browse our collection to discover more content in these categories.
Video Information
Views
129
Likes
4
Duration
0:10
Published
Mar 30, 2025
Related Trending Topics
LIVE TRENDSRelated trending topics. Click any trend to explore more videos.
No specific trending topics match this video yet.
Explore All Trends