Unlocking LLM Inference: The Hidden Math Behind Model Serving 🚀
Discover the fundamentals of LLM inference arithmetic and learn how parameters are counted in large language models. Join Luca Baggi at PyData London 2025 to deepen your understanding of model serving techniques.

PyData
714 views • Jun 30, 2025
About this video
www.pydata.org
LLM Inference Arithmetics: the Theory behind Model Serving
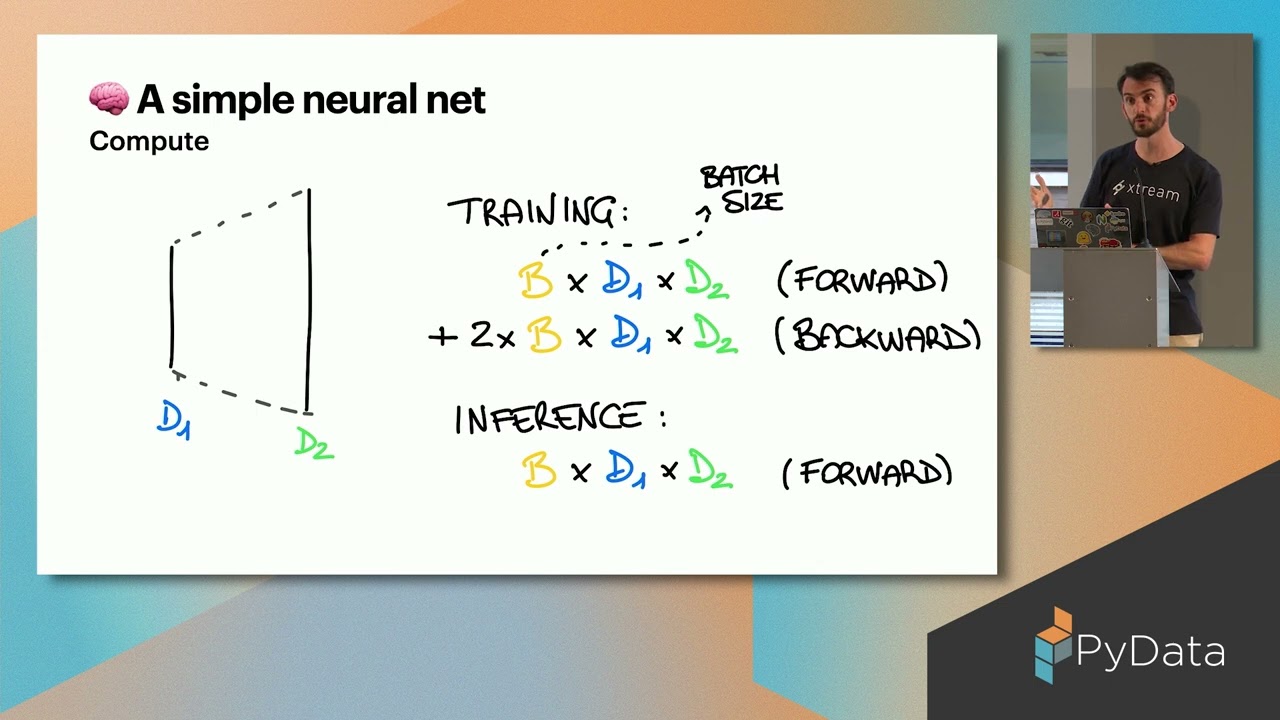
Have you ever asked yourself how parameters for an LLM are counted, or wondered why Gemma 2B is actually closer to a 3B model? You have no clue about what a KV-Cache is? (And, before you ask: no, it's not a Redis fork.) Do you want to find out how much GPU VRAM you need to run your model smoothly?
If your answer to any of these questions was "yes", or you have another doubt about inference with LLMs - such as batching, or time-to-first-token - this talk is for you. Well, except for the Redis part.
PyData is an educational program of NumFOCUS, a 501(c)3 non-profit organization in the United States. PyData provides a forum for the international community of users and developers of data analysis tools to share ideas and learn from each other. The global PyData network promotes discussion of best practices, new approaches, and emerging technologies for data management, processing, analytics, and visualization. PyData communities approach data science using many languages, including (but not limited to) Python, Julia, and R.
PyData conferences aim to be accessible and community-driven, with novice to advanced level presentations. PyData tutorials and talks bring attendees the latest project features along with cutting-edge use cases.
LLM Inference Arithmetics: the Theory behind Model Serving
Have you ever asked yourself how parameters for an LLM are counted, or wondered why Gemma 2B is actually closer to a 3B model? You have no clue about what a KV-Cache is? (And, before you ask: no, it's not a Redis fork.) Do you want to find out how much GPU VRAM you need to run your model smoothly?
If your answer to any of these questions was "yes", or you have another doubt about inference with LLMs - such as batching, or time-to-first-token - this talk is for you. Well, except for the Redis part.
PyData is an educational program of NumFOCUS, a 501(c)3 non-profit organization in the United States. PyData provides a forum for the international community of users and developers of data analysis tools to share ideas and learn from each other. The global PyData network promotes discussion of best practices, new approaches, and emerging technologies for data management, processing, analytics, and visualization. PyData communities approach data science using many languages, including (but not limited to) Python, Julia, and R.
PyData conferences aim to be accessible and community-driven, with novice to advanced level presentations. PyData tutorials and talks bring attendees the latest project features along with cutting-edge use cases.
Video Information
Views
714
Likes
17
Duration
33:40
Published
Jun 30, 2025
Related Trending Topics
LIVE TRENDSRelated trending topics. Click any trend to explore more videos.