Master Data Preprocessing in Machine Learning with Python: SimpleImputer, OneHotEncoder & More 🚀
Learn essential data preprocessing techniques in Python for machine learning, including handling missing data, encoding categorical variables, and splitting datasets. Boost your model accuracy today! Check out the GitHub repo and Google Colab notebook for

Bibhuti Ghimire
136 views • Apr 19, 2023
About this video
GitHub: https://github.com/bibhutighimire/Data-Preprocessing-in-Machine-Learning-using-Python
Google Collab: https://colab.research.google.com/drive/1e1sKsVO-26kicMXbdq6aoe_shlgsxWhx#scrollTo=fGOiYH95ojot
Data Preprocessing in Machine Learning using Python 2023
#SimpleImputer #OneHotEncoder #train_test_split #StandardScaler #LabelEncoder
Website: https://www.javatpoint.com/how-to-get-datasets-for-machine-learning
//Import Library:
import pandas as pd
import numpy as np
//Import Dataset:
dataset = pd.read_csv('Data.csv')
print(dataset)
//Split dataset into X and y i.e. independent and dependent model
X = dataset.iloc[:,:-1].values
print(X)
y = dataset.iloc[:,-1].values
print(y)
//Handling missing data:
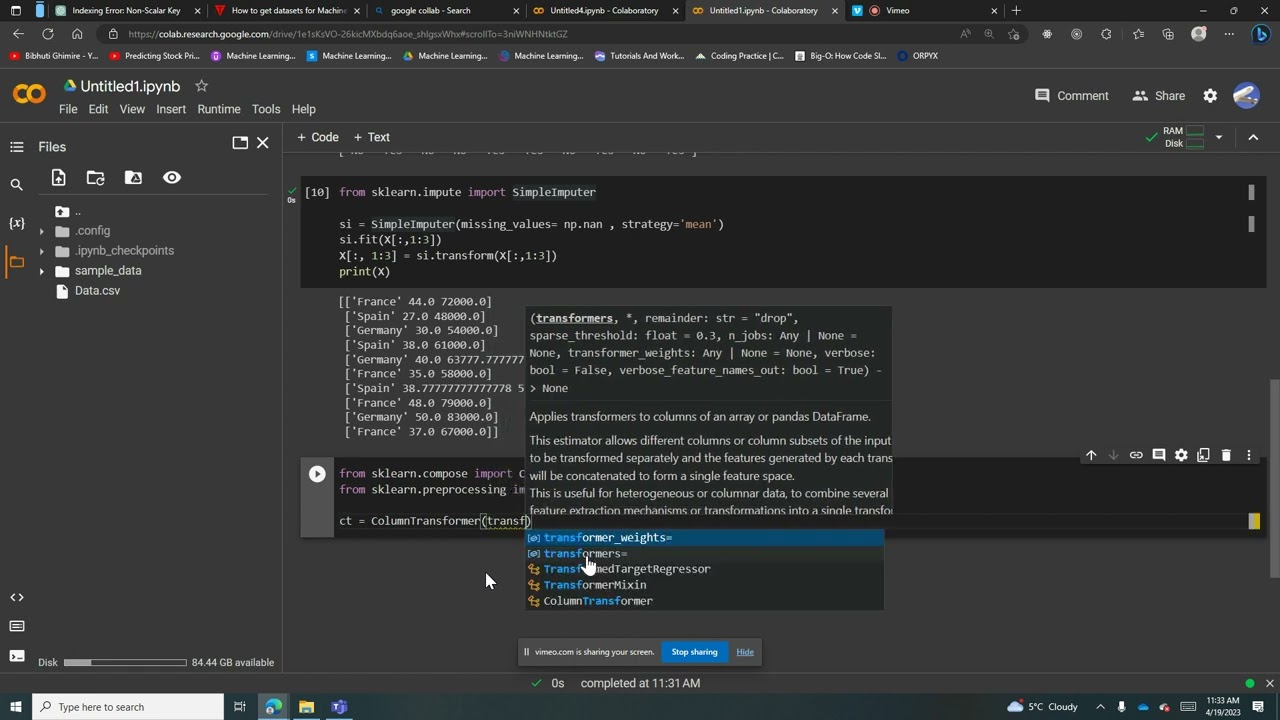
from sklearn.impute import SimpleImputer
si = SimpleImputer(missing_values= np.nan , strategy='mean')
si.fit(X[:,1:3])
X[:, 1:3] = si.transform(X[:,1:3])
print(X)
//Encoding categorical data:
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import OneHotEncoder
ct = ColumnTransformer(transformers=[('encoder', OneHotEncoder(), [0])] , remainder= 'passthrough')
X = ct.fit_transform(X)
print(X)
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
y = le.fit_transform(y)
print(y)
//Splitting data into training and testing model:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1)
print(X_train)
print(y_train)
print(y_test)
print(X_test)
//Feature Scaling:
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
X_train[:,3:5] = ss.fit_transform(X_train[:,3:5])
X_test[:,3:5] = ss.transform(X_test[:,3:5])
print(X_train)
print(X_test)
Google Collab: https://colab.research.google.com/drive/1e1sKsVO-26kicMXbdq6aoe_shlgsxWhx#scrollTo=fGOiYH95ojot
Data Preprocessing in Machine Learning using Python 2023
#SimpleImputer #OneHotEncoder #train_test_split #StandardScaler #LabelEncoder
Website: https://www.javatpoint.com/how-to-get-datasets-for-machine-learning
//Import Library:
import pandas as pd
import numpy as np
//Import Dataset:
dataset = pd.read_csv('Data.csv')
print(dataset)
//Split dataset into X and y i.e. independent and dependent model
X = dataset.iloc[:,:-1].values
print(X)
y = dataset.iloc[:,-1].values
print(y)
//Handling missing data:
from sklearn.impute import SimpleImputer
si = SimpleImputer(missing_values= np.nan , strategy='mean')
si.fit(X[:,1:3])
X[:, 1:3] = si.transform(X[:,1:3])
print(X)
//Encoding categorical data:
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import OneHotEncoder
ct = ColumnTransformer(transformers=[('encoder', OneHotEncoder(), [0])] , remainder= 'passthrough')
X = ct.fit_transform(X)
print(X)
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
y = le.fit_transform(y)
print(y)
//Splitting data into training and testing model:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1)
print(X_train)
print(y_train)
print(y_test)
print(X_test)
//Feature Scaling:
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
X_train[:,3:5] = ss.fit_transform(X_train[:,3:5])
X_test[:,3:5] = ss.transform(X_test[:,3:5])
print(X_train)
print(X_test)
Video Information
Views
136
Likes
3
Duration
28:08
Published
Apr 19, 2023
Related Trending Topics
LIVE TRENDSRelated trending topics. Click any trend to explore more videos.
No specific trending topics match this video yet.
Explore All Trends