CNCF On-Demand: Scalable LLM Deployment with KServe 🚀
Explore how KServe enables scalable, cost-effective inference for large language models, surpassing traditional serving limitations.

CNCF [Cloud Native Computing Foundation]
1.4K views • Dec 4, 2025
About this video
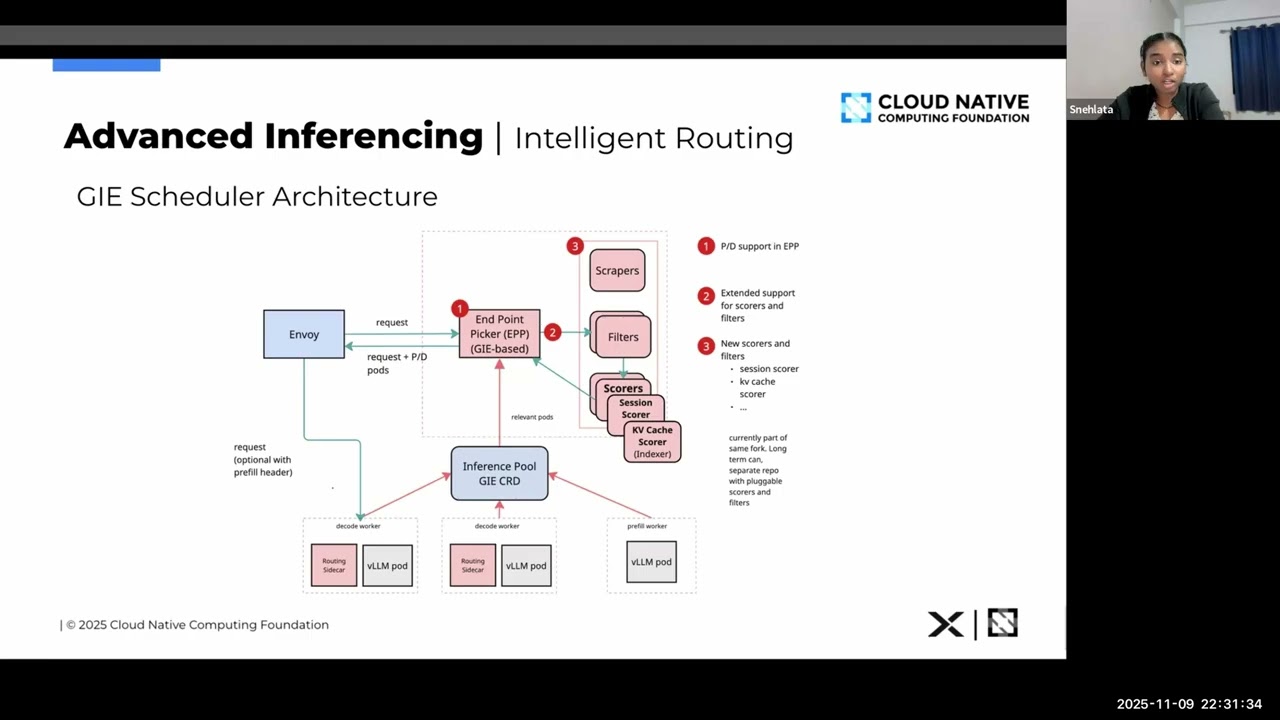
The demand for scalable and cost-efficient inference of large language models (LLMs) is outpacing the capabilities of traditional serving stacks. Unlike conventional ML workloads, LLM inference brings unique challenges: long prompts, token-by-token generation, bursty traffic patterns, and the need for consistently high GPU utilization. These factors make request routing, deterministic scheduling, and autoscaling significantly more complex than typical model serving scenarios. In this presentation, we will discuss Kserve, an open source project for LLM Inference at scale.
* Scalable model serving on Kubernetes using KServe.
* Seamless integration with Kubernetes, enabling reproducible, resilient, and cost- efficient deployments.
* Deterministic scheduling and token-aware request handling through the Kubernetes inference scheduler (using Gateway Inference Extension) and execution strategies.
* Distributed and Disaggregated Inferencing with LLM Inference Service for advance serving.
* Scalable model serving on Kubernetes using KServe.
* Seamless integration with Kubernetes, enabling reproducible, resilient, and cost- efficient deployments.
* Deterministic scheduling and token-aware request handling through the Kubernetes inference scheduler (using Gateway Inference Extension) and execution strategies.
* Distributed and Disaggregated Inferencing with LLM Inference Service for advance serving.
Video Information
Views
1.4K
Likes
22
Duration
18:30
Published
Dec 4, 2025
User Reviews
4.5
(1) Related Trending Topics
LIVE TRENDSRelated trending topics. Click any trend to explore more videos.
No specific trending topics match this video yet.
Explore All Trends