Alibaba's Deployment of Apache Hadoop YARN 3.x for Large-Scale Data Infrastructure
Since 2013, Alibaba has utilized Apache Hadoop YARN 3.x to construct its data infrastructure, now managing over 10,000 nodes. Hadoop YARN supports various data processing workloads within Alibaba's extensive ecosystem.

DataWorks Summit
426 views • Jul 23, 2018
About this video
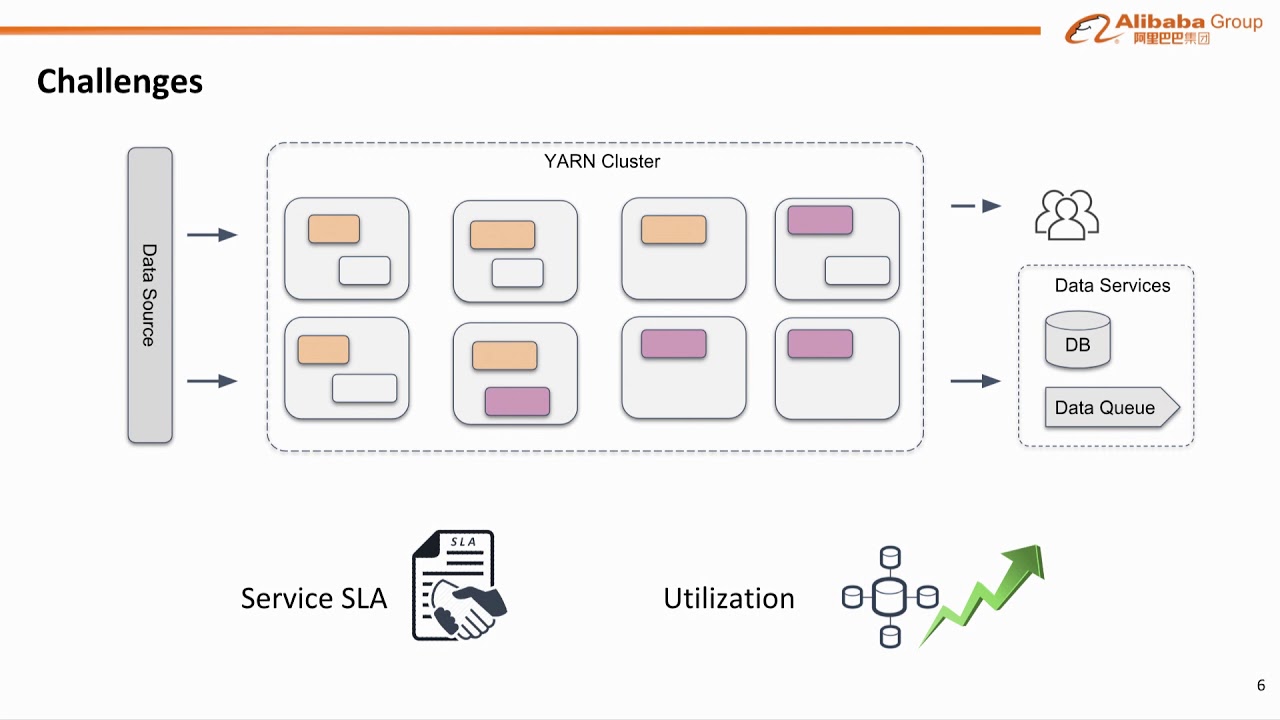
Alibaba builds the data infrastructure with Apache Hadoop YARN since 2013, and till now it manages more than 10k nodes. In Alibaba, Hadoop YARN serves various systems such as search, advertising, and recommendation etc. It runs not just batch jobs, also streaming, machine learning, OLAP, and even online services that directly impact Alibaba’s user experience. To extend YARN’s ability to support such complex scenarios, we have done and leveraged a lot of YARN 3.x improvements. In this talk, you will find what are these improvements and how they helped to solve difficult problems in large production clusters.
This includes:
1. Highly improved performance with Capacity Scheduler’s async scheduling framework
2. Better placement decisions with node attributes, placement constraints
3. Better resource utilization with opportunistic containers
4. Introduce a load balancer to balance resource utilization
5. Generic resource types scheduling/isolation to manage new resources such as GPU and FPGA
In the presentation, we will further introduce how we build the entire ecosystem on top of YARN and how we keep evolving YARN’s ability to tackle the challenges brought by continuously increasing data and business in Alibaba.
This includes:
1. Highly improved performance with Capacity Scheduler’s async scheduling framework
2. Better placement decisions with node attributes, placement constraints
3. Better resource utilization with opportunistic containers
4. Introduce a load balancer to balance resource utilization
5. Generic resource types scheduling/isolation to manage new resources such as GPU and FPGA
In the presentation, we will further introduce how we build the entire ecosystem on top of YARN and how we keep evolving YARN’s ability to tackle the challenges brought by continuously increasing data and business in Alibaba.
Tags and Topics
Browse our collection to discover more content in these categories.
Video Information
Views
426
Likes
5
Duration
38:27
Published
Jul 23, 2018
Related Trending Topics
LIVE TRENDSRelated trending topics. Click any trend to explore more videos.
Trending Now